The complexity and interdisciplinary nature of Integrated Energy Systems (IES) pose significant challenges for scientific research. Existing general-purpose Large Language Models (LLMs) lack domain depth, while industry-specific models lack the necessary logic for scientific inquiry, failing to meet the needs of researchers. To bridge this gap, this study develops EnerAgentic, a research assistant for the IES domain. We first constructed a multi-source domain knowledge base comprising academic literature, textbooks, and simulation code. Using a Generator-Validator agent pipeline, we automatically built a high-quality Supervised Fine-Tuning dataset of approximately 56,000 samples. Based on this, we fine-tuned the Qwen3-14B-Base model using SFT and integrated a Retrieval-Augmented Generation framework. Evaluation results show that EnerAgentic comprehensively outperforms its base model and other open-source models on general benchmarks. Crucially, in the domain-specific evaluation, EnerAgentic-RAG achieved an accuracy of 78.50%, a significant improvement over the base model’s 45.00%. This study validates the effectiveness of our approach, demonstrating that EnerAgentic possesses the core capabilities to serve as a research assistant, providing intelligent, end-to-end support for complex data analysis, knowledge retrieval, and simulation modeling in the IES field.
1 Introduction
Integrated Energy Systems (IES) have become a crucial development direction for modern energy systems due to their technological characteristics of multi-energy complementarity, high efficiency, and low carbon. Driven by global carbon neutrality goals, IES rely on big data analytics, artificial intelligence technologies, and advanced sensing networks to achieve intelligent management and optimal dispatch across the entire process of energy production, transmission, storage, and consumption, significantly enhancing system operational efficiency and reliability. However, IES involve the deep interdisciplinary integration of knowledge from multiple fields such as energy, electrical engineering, economics, and management science. Its knowledge base is characterized by fragmentation and rapid evolution, posing significant challenges to scientific research and education.
In recent years, artificial intelligence technologies related to Large Language Models (LLMs) have developed rapidly, leading to the emergence of many general-purpose models, including LLaMA [1], Deepseek [2], Baichuan [3], and Qwen [4]. These general-purpose LLMs possess excellent semantic understanding and knowledge reasoning capabilities and can efficiently integrate multidisciplinary knowledge. However, in scientific research practice, the performance of these general-purpose models in the IES domain is not ideal. Their responses often lack sufficient generalization ability and show significant deficiencies in depth and precision within this vertical domain. This limitation primarily stems from the lack of reliable knowledge in the integrated energy domain within their training corpora, leading to the models lacking necessary domain context and physical constraints.
The rapid development and refinement of domain-specific large models for the energy sector have, to some extent, compensated for the deficiencies of general-purpose models. Their depth and precision in the vertical domain are sufficient to address specialized industry problems, and they even possess capabilities for understanding, integrating, and outputting multi-modal data. For example, Baidu AI Cloud and the State Grid Corporation of China jointly created the “Guangming Power Large Model,” the nation’s first hundred-billion-level multi-modal power model, covering a wealth of industry data including text, images, and time-series to promote the digital and intelligent transformation of the power industry.
However, the applications of these domain-specific models are concentrated on industrial production and enterprise operation and maintenance. The resulting trained models generally lack scientific research logic, exhibiting issues such as non-interactive answers, simplistic feedback formats, and brief reasoning processes. They fail to meet the personalized needs of researchers and university students, making them equally unsuitable for the role of a professional-domain research assistant.
To address the difficulties in scientific research, industry decision-making, and other aspects within the IES domain, we have developed EnerAgentic, a research assistant oriented towards the vertical domain of integrated energy systems. Utilizing a self-built, high-quality domain dataset, the model training was completed by integrating steps such as Supervised Fine-Tuning (SFT) and Retrieval-Augmented Generation (RAG). It can not only act as a knowledgeable industry expert to provide precise answers but also automatically parse figures and tables from literature, quickly organize knowledge frameworks, and generate simulation code to implement complex data modeling and power flow calculations, aiming to provide end-to-end intelligent assistance for researchers in the IES field.
2 Related Work
2.1 Applications of Large Language Models in Vertical Scientific Domains
In recent years, Large Language Models (LLMs) have rapidly evolved from general-purpose domains to specialized, vertical fields. Researchers have significantly enhanced model performance on specific scientific tasks through domain-specific knowledge fine-tuning. For example, in the power systems domain, Yin et al. [5]fine-tuned the LLaMA model with Chinese and power-domain knowledge, enabling it to demonstrate outstanding performance in tasks such as text generation, summarization, and topic identification. In the building energy sector, Zhang et al. [6]utilized SHAP (Shapley Additive Explanations) technology combined with LLMs to address the “black-box” problem of artificial intelligence control in HVAC (Heating, Ventilation, and Air Conditioning) systems, and to generate interpretable narrative technical reports. The JARVIS framework, developed by Lee et al. [7], achieves complex question-answering and interaction regarding HVAC sensor data through the collaboration of “expert LLMs” and “agents.”
This trend is equally evident in other scientific fields. OceanGPT, the first large-scale oceanographic model released by Zhen et al. [8], showcased the professionalism of LLMs in handling marine science Q&A and content generation. These works demonstrate that domain-specific fine-tuning is a critical step for the successful application of LLMs in engineering and science.
2.2 LLM Agents for Autonomous Scientific Research
The capability of LLMs to assist in scientific research has evolved from simple text processing to more complex, structured research tasks. The AutoSurvey system, developed by Wang et al. [9]from Westlake University, utilizes multi-model evaluation to achieve the automated writing of academic literature reviews. The DeepReviewer-14B model, trained by Zhu et al. [10]from Zhejiang University, enhances the reliability of automated paper reviewing by imitating the human expert review process.
Furthermore, researchers have begun to explore Autonomous Research Agents. For instance, the Agent Laboratory framework proposed by Schmidgall et al. [11]constructs an LLM agent capable of autonomously completing literature reviews, experiment execution, and report writing. In the energy field, the RePower platform developed by Liu et al. [12]from Tsinghua University is an LLM-driven autonomous research platform capable of independently executing data-driven research tasks such as parameter prediction and optimization in the power systems domain. These works highlight the immense potential of LLMs as “research assistants”.
2.3 LLM Applications and Research Gaps in Integrated Energy Systems
Although LLMs have made progress in single-energy domains (e.g. power and buildings), their application in the more complex, interdisciplinary field of IES is still in its nascent stages. IES involves the coupling and optimization of multiple energy carriers—such as electricity, gas, heat, and hydrogen—which places higher demands on the model’s cross-domain knowledge understanding and complex reasoning abilities. Recently, some work has begun to explore Multi-Agent frameworks to solve complex energy problems. For example, the GridMind system proposed by Jin et al. [13]is a multi-agent AI system that integrates LLMs with deterministic engineering solvers to assist in power system analysis.
However, there is currently no multi-agent framework specifically designed for IES research tasks that integrates multi-source knowledge retrieval, complex data analysis, simulation tool invocation, and academic content generation. The EnerAgentic proposed in this study aims to fill this gap. By constructing a multi-agent collaborative system, it provides end-to-end intelligent assistance for researchers in the IES field.
3 EnerAgentic
This section elaborates on the complete construction process of EnerAgentic, which revolves around four core technical modules. The first is Domain Instruction Data Generation (3.1); as the foundation of the model, this stage involved constructing a multi-source IES corpus and subsequently employing a “Generator-Validator” agent pipeline to automatically build a SFT instruction dataset containing approximately 56,000 high-quality samples. The second module is Model Fine-Tuning (3.2), where we selected Qwen3-14B-Base as the base model. Utilizing the LLaMA Factory framework, we conducted efficient and stable training by synergistically applying LoRA (Low-Rank Adaptation) technology, NEFTune and Dropout regularization methods, and a cosine annealing learning rate strategy. The third module is Multi-modal Document Parsing (3.3), which equips EnerAgentic with the ability to process complex documents by integrating OCR, TSR (Table Structure Recognition), and DLR (Document Layout Recognition) technologies to convert files like scanned PDFs into structured Markdown format. Finally, the RAG (3.4) module employs the RAPTOR recursive retrieval method, enabling the model to fetch precise context from the domain knowledge base, thereby enhancing answer accuracy and mitigating “hallucinations”.
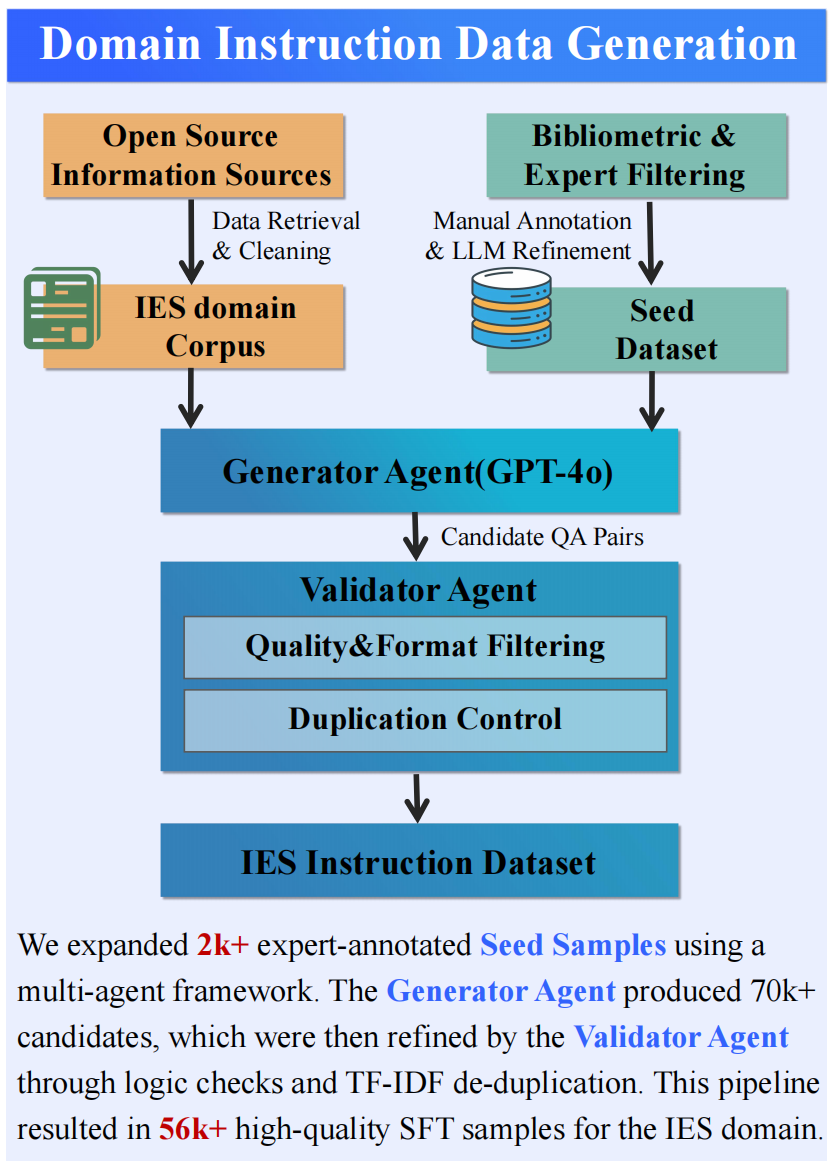
3.1 Domain Instruction Data Generation
3.1.1 Constructing the Integrated Energy System Corpus
To equip the model with the capabilities of a research assistant, this study constructed a multi-source, heterogeneous domain corpus for IES. Its composition includes: 1) authoritative academic literature, such as representative reviews and highly cited papers; 2) specialized textbooks, industry standards, and government white papers; and 3) engineering-side materials, such as open-source code repositories and technical documentation for simulation software like Matpower and Pandapower, intended to enhance the model’s abilities in code generation and engineering practice.
The construction of the corpus followed a “Retrieve-Filter-Clean” pipeline.
In the data retrieval phase, we conducted searches based on databases such as Web of Science, IEEE Xplore, ScienceDirect, and CNKI, using keywords like “Integrated Energy System.” To ensure the contemporary relevance of the corpus, the literature’s time span was limited to 2015 to 2025.
In the data filtering phase, to ensure the core relevance of the literature, this study adopted a multi-stage filtering strategy combining bibliometrics with manual expert judgment.
We first applied Reference Co-citation Analysis [14]to identify authoritative literature and knowledge structures within the domain. Concurrently, we conducted Keyword Co-occurrence Analysis, precisely locating the current research hotspots and core topics by analyzing the co-occurrence network of keywords appearing more than 15 times.
Based on the SOTA (State-of-the-Art) results from the aforementioned bibliometric analysis, researchers further manually reviewed the titles, abstracts, and keywords of the literature, removing documents with low relevance. Ultimately, 201 high-quality Chinese articles and 196 high-quality English articles were selected as the core academic corpus.
In the data cleaning phase, to eliminate interference from irrelevant content during model training, all documents underwent pre-processing and cleaning. We used tools such as MinerU to parse the source PDF files into structured Markdown format, a process that fully preserved text and tabular information. Simultaneously, non-knowledge content such as headers, footers, URLs, author biographies, and reference lists were uniformly deleted. The processed corpus precisely focuses on the core knowledge of IES, providing a solid data foundation for subsequent model training.
3.1.2 Generating the Seed Dataset
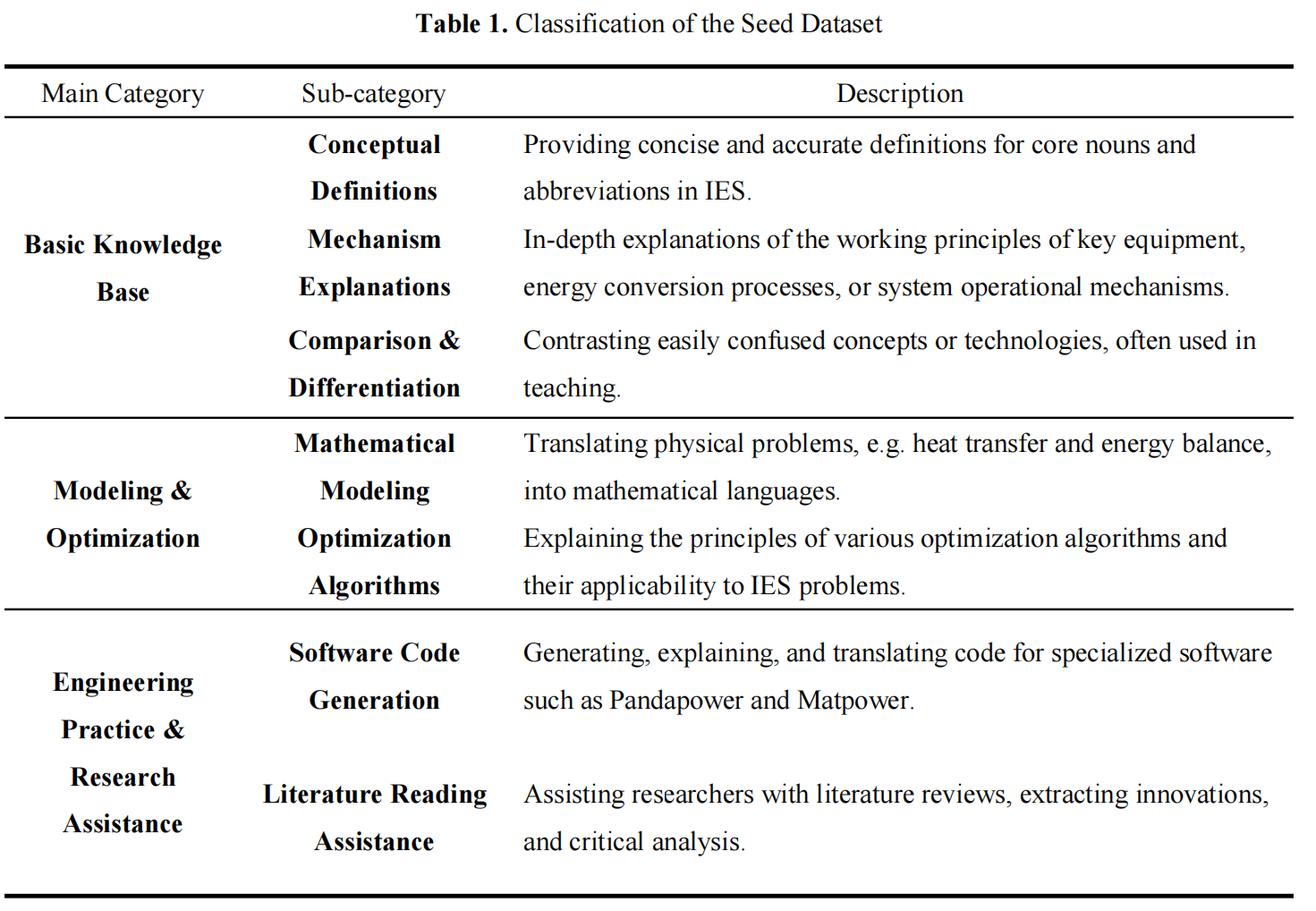
In the generation of the seed dataset, we manually categorized the IES data into the following three main categories and seven sub-categories based on the domain’s research needs. These categories are detailed in Table 1.
Based on the content above, we hired several expert scholars with extensive backgrounds in IES. Each expert was responsible for annotating and generating seed data for specific categories. During this process, LLMs were used to supplement and refine the existing data, which was finally approved after manual review by the experts. This process took approximately 3 days, ultimately yielding about 2k+ seed data samples across 3 main categories and 7 sub-categories.
3.1.3 Generator Agent
Based on the content of the seed dataset and the vertical domain corpus, we designed a Generator Agent to produce candidate question-answer pairs.
In the process of building a high-quality dataset, accurate and high-caliber prompts play a crucial role. Leveraging the previously selected seed dataset, the Generator Agent calls the GPT-4o model’s API to generate prompts for data construction. These prompts focus on IES, incorporating elements like question format, background information, and task objectives, to guide the model in generating QA pairs for typical scenarios such as energy management, storage optimization, and demand response. High-quality prompts provide context and structured information, improving the relevance and accuracy of the generated results, while also offering a reference pattern for model training, ensuring consistency, and reducing the complexity of the generation task.
Based on the generated high-quality prompts, the Generator Agent embeds the QA pairs from the pre-processed text documents into the prompts as reference context. It calls the LLM’s API to generate candidate QA pairs. In this study, the Generator Agent utilized GPT-4o to generate these candidate pairs. For each call, the agent sends a request to the LLM API containing the prompt template, seed data, and generation parameters (e.g. temperature, max length, etc.), and receives the resulting text. This ultimately generated approximately 70,000 candidate QA pairs. These candidates cover multiple key scenarios in the IES domain, such as energy management, storage optimization, and demand response, providing abundant material for subsequent data filtering and model training.
3.1.4 Validator Agent
To ensure the quality and diversity of the fine-tuning dataset, this study designed a Validator Agent that includes quality filtering and duplication control, used to process the candidate QA pairs produced by the Generator Agent. This validation process is divided into two stages:
Stage 1: Quality and Format Filtering. This stage leverages the evaluation capabilities of LLMs. The system calls the GPT-4o API to automatically assess the semantic coherence, logical correctness, formatting regularity, and answer relevance of the candidate QA pairs. Samples judged as “unqualified” by GPT-4o—such as those with incoherent semantics, irrelevant question-answer pairs, or formatting errors—are directly discarded.
Stage 2: Duplication Control and De-duplication. To address the issue of semantic repetition, this stage employs TF-IDF-based text similarity detection. First, the process concatenates the instruction and output fields of each QA-Pair that passed the first stage into a single text document, building a corpus for de-duplication. Subsequently, we use the TfidfVectorizer class from the scikit-learn library, specifying jieba as the Chinese tokenizer, to efficiently convert the entire corpus into a TF-IDF vector matrix. By calculating the cosine similarity between vectors in this matrix, we can quantify the semantic overlap between samples. In this study, a similarity threshold was set to 0.7. When the similarity score of any two QA pairs exceeded this threshold, the system deemed them highly similar and retained only one representative sample.
After these two stages of rigorous filtering, we finally constructed a high-quality IES domain instruction fine-tuning dataset containing approximately 56,000 samples.
3.2 Fine-Tuning
EnerAgentic selected Qwen3-14B-Base as the base model and was trained on a server equipped with two NVIDIA A6000 GPUs. To achieve efficient and stable fine-tuning, this study adopted a comprehensive strategy integrating Low-Rank Adaptation (LoRA), regularization, and dynamic learning rate scheduling.
Regarding the fine-tuning framework, we chose the LLaMA Factory framework and employed LoRA [15]technology. The core idea of LoRA is to freeze the vast majority of the pre-trained model’s weights, introducing only small-scale, low-rank trainable matrices (Trainable Rank-Decomposition Matrices) in specific layers (such as attention layers) to approximate the weight updates. During the training process, only the parameters of these newly added low-rank matrices are updated. This method preserves the rich knowledge of the pre-trained model while significantly reducing the computational resources and memory overhead required for fine-tuning, achieving performance comparable to full-parameter fine-tuning.
To effectively suppress the overfitting that may occur during the Supervised Fine-Tuning (SFT) phase, we combined two regularization techniques. First, we employed the classic Dropout method, which randomly “freezes” a portion of neurons at a certain probability during training iterations. This forces the network to learn more robust feature representations and prevents the “co-adaptation” phenomenon among neurons. Second, we introduced NEFTune [16] (Noise Embedding for Fine-Tuning) technology, which injects a small amount of random noise into the output vectors of the Embedding Layer during training. This slight perturbation to the input representations increases the training difficulty, effectively preventing the model from “memorizing” the limited training samples and thereby enhancing its generalization ability.
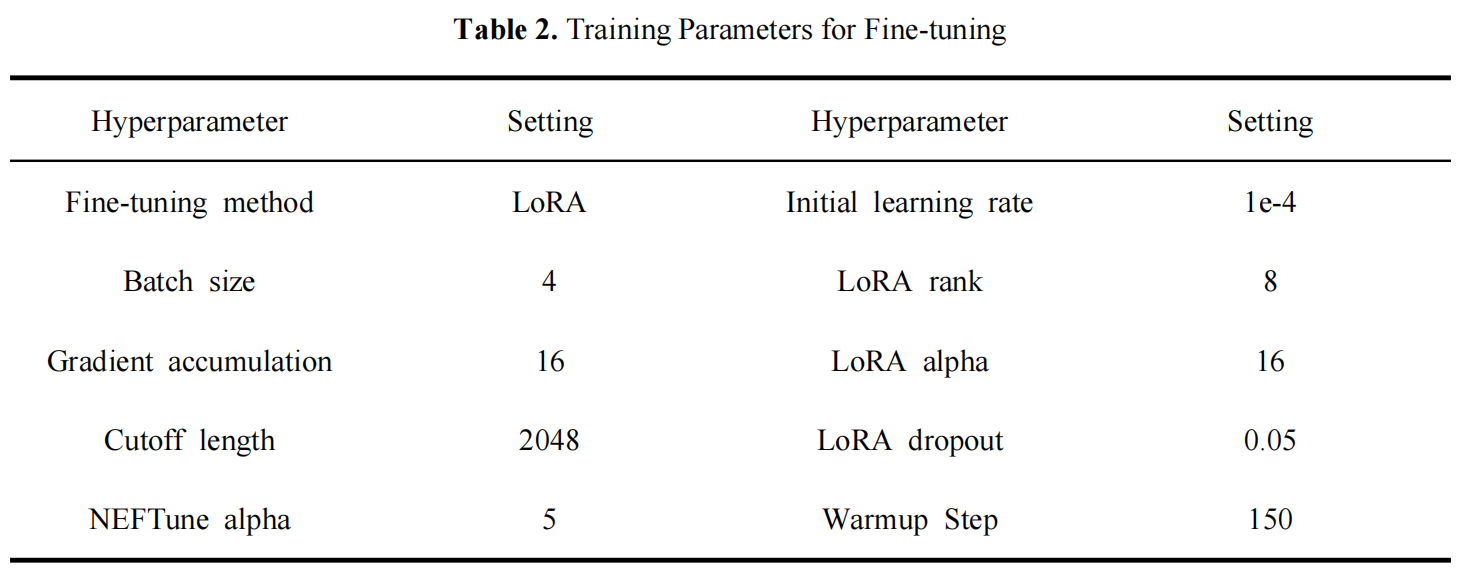
Finally, to ensure training stability and accelerate convergence, we adopted a learning rate scheduling strategy that combines Warm-up and Cosine Annealing. In the initial phase of training, the warm-up stage starts with a low initial learning rate and gradually increases it to the preset value, effectively avoiding potential gradient explosions or training divergence that might occur when model parameters are not yet stable. After the warm-up phase, the cosine annealing strategy takes over the learning rate, causing it to decay smoothly according to a cosine function curve as the training steps progress. This dynamic “rise-then-fall” adjustment mechanism helps the model explore the local minima of the loss function more finely in the later stages of training, enhancing the final convergence effect.The remaining fine-tuning training parameters are shown in Table 2.
3.3 Multi-modal Document Parsing
To enable deep understanding and retrieval of diverse documents in the energy domain, the EnerAgentic model integrates an efficient document pre-processing and vectorization pipeline.
In the document pre-processing stage, the system must handle multiple input formats, including Word, text-based PDFs, scanned PDFs, and images containing text. For scanned PDFs and image files, the system employs Optical Character Recognition (OCR) technology to extract text. To ensure the structural integrity of the content, the module further combines Table Structure Recognition (TSR) and Document Layout Recognition (DLR) technologies. This process not only extracts textual information but also fully preserves the original document’s hierarchical structure, such as headings, paragraphs, lists, and tables. All extracted content is finally converted into a unified Markdown format to facilitate subsequent parsing, rendering, and indexing.
In the text vectorization stage, the system converts the structured Markdown text into searchable numerical vectors. The core function of an Embedding Model is to map unstructured text into low-dimensional, high-density embedding vectors. This study selected all-MiniLM-L6-v2 as EnerAgentic’s embedding model. It is a lightweight model from the Sentence-Transformers library [17], optimized based on Microsoft’s MiniLM architecture.
The primary basis for selecting all-MiniLM-L6-v2 lies in its balance of efficiency and performance. The model’s small parameter size allows it to run efficiently even in CPU environments. Despite its lightweight nature, its performance on semantic similarity and text retrieval tasks approaches that of large BERT-base models and significantly surpasses traditional embedding methods like Word2Vec and GloVe. This highly aligns with the requirement for efficient deployment while controlling costs.
3.4 RAG
To address the inherent knowledge limitations and “hallucination” problems of LLMs, EnerAgentic integrates the Retrieval-Augmented Generation (RAG) framework [18]. The core mechanism of this framework is that, before generating an answer, the model first retrieves relevant information from an external professional knowledge base and uses it as dynamic context. This significantly enhances the answer’s accuracy, timeliness, and traceability. This study constructed a specialized knowledge base for the IES domain, reusing the data from the IES corpus described in Section 3.1.1, and selecting papers and reviews with high reference co-citation counts, as well as factual data and information from technical manuals.
However, traditional RAG methods exhibit limitations when handling complex, multi-step reasoning question-answering tasks within the energy domain. In such tasks, a semantic gap often exists between the relevant text chunks for the question and the answer, leading to reduced retrieval matching precision and the loss of critical details. To overcome this challenge, EnerAgentic adopted the RAPTOR (Recursive Abstractive Processing for Tree Organized Retrieval) retrieval method [19]. RAPTOR is a recursive abstractive processing technique that constructs a hierarchical knowledge index in a bottom-up manner. The method begins with fine-grained raw text chunks, progressively distills and generates coarse-grained summaries, and ultimately forms a structured content tree. This tree-like index structure enables EnerAgentic to balance global semantic understanding with local detail comprehension for long documents during retrieval, effectively resolving the issues of long-context information overload and context fragmentation, and significantly improving retrieval performance for complex queries.
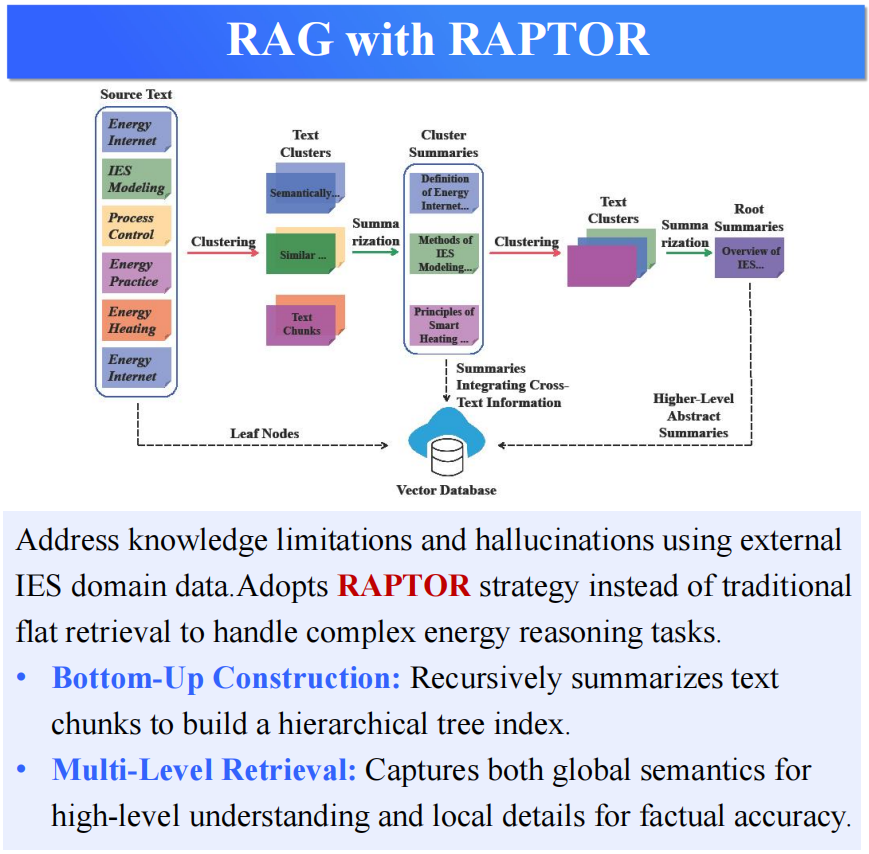
4 Model Capability Assessment
To evaluate the model’s ability to perform tasks related to IES, we established a comprehensive capability assessment framework. This framework is structured around six key dimensions: instruction-following, code generation, disciplinary computation, tool interaction, logical reasoning, and Chinese understanding. Building on this framework, we designed two evaluation components: a general-purpose benchmark suite and a domain-specific benchmark suite, to comprehensively examine the overall performance of EnerAgentic.
4.1 General Capability Assessment
In the general capability assessment, we selected a total of ten general benchmarks. To evaluate the model’s Chinese understanding ability, we selected CMMLU [20] and CEval [21], two large-scale Chinese multi-task benchmarks. To assess disciplinary computation and logical reasoning, we used GSM8K [22] and MATH-500 [23] to test mathematical problem-solving. This was supplemented by BBH [24], ARC [25], and Super-GPQA [26] to examine the model’s performance in complex reasoning, scientific question-answering, and advanced professional knowledge. To evaluate code generation capability, we used Live-Code-Bench [27], which focuses on assessing real-time code generation and fixing. To assess tool interaction ability, we selected Tool-Bench [28] to test the model’s capacity for executing complex tool calls. Finally, to evaluate instruction-following and commonsense reasoning, we included HellaSwag [29].
The evaluation results are shown in the Fig. 2. The experiments demonstrate that EnerAgentic significantly surpassed the performance of the comparative models—Qwen3-14B-Base, DeepSeek-R1-Distill-Qwen-14B, and Llama3-8B-Instruct—across all ten general capability benchmarks.
Compared to its base model, Qwen3-14B-Base, EnerAgentic achieved significant performance improvements on all test items. This strongly proves that the SFT strategy adopted in this study not only enhanced the model’s domain knowledge but also comprehensively improved its underlying general capabilities, especially in dimensions such as disciplinary computation (GSM8K, MATH-500), logical reasoning (BBH, ARC), and code generation (Live-Code-Bench).
Furthermore, EnerAgentic demonstrated a leading edge in its scores, whether in Chinese understanding, commonsense reasoning, or complex tool-use tasks. This indicates that after domain instruction fine-tuning, our model’s comprehensive capabilities have reached or surpassed the level of current mainstream open-source models.
4.2 Domain-Specific Capability Assessment
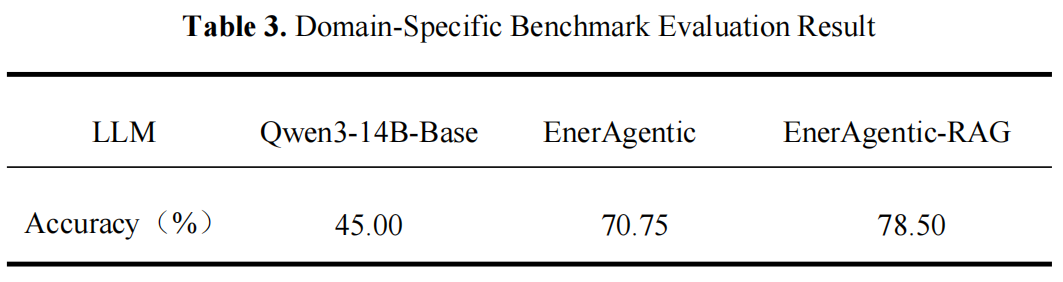
To systematically evaluate EnerAgentic’s performance in the specialized domain of Integrated Energy Systems, the team developed a domain-specific benchmark. This benchmark consists of 400 objective questions, focusing on aspects such as professional knowledge, reasoning ability, data processing, and practical application.
The evaluation results are shown in the Table 3. The base model achieved an accuracy of 45.00% on the specialized dataset, indicating that general-purpose large models severely lack the specialized knowledge of the IES domain and cannot answer professional questions accurately. The fine-tuned EnerAgentic model achieved an accuracy of 70.75%, which confirms that SFT significantly infused the model with domain knowledge and research logic. After integrating the RAG framework on top of the SFT model, the EnerAgentic-RAG model’s accuracy reached 78.50%. This demonstrates that RAG, serving as an external knowledge base, effectively compensated for the deficiencies in the model’s parametric knowledge and further improved the answer’s accuracy and reliability.
Therefore, in terms of performance, EnerAgentic exhibits better mathematical reasoning and instruction-following abilities than open-source large models. It also performs excellently on the domain-specific dataset, possessing strong capabilities for handling IES tasks.
5 Conclusion
This study successfully designed and constructed EnerAgentic, a LLM research assistant oriented toward the vertical domain of IES. To address the pain points of general-purpose models lacking domain knowledge and research logic, this study first constructed a multi-source domain knowledge base comprising academic literature, professional textbooks, and simulation code. Subsequently, we innovatively employed a “Generator-Validator” agent pipeline to automatically construct a high-quality SFT instruction dataset containing approximately 56,000 samples. Based on this, we conducted efficient SFT on the Qwen3-14B-Base model and combined it with a RAG framework based on RAPTOR recursive retrieval to enhance the model’s knowledge accuracy and suppress “hallucinations”.
The model capability assessment results fully validate the effectiveness of our technical route. In the general capability benchmarks, EnerAgentic significantly surpassed its base model and other similar open-source models across ten dimensions, including disciplinary computation, code generation, and logical reasoning. In the critical domain-specific capability assessment, EnerAgentic (SFT) achieved a performance leap of over 25 percentage points compared to the base model (from 45.00% to 70.75%), while EnerAgentic-RAG further increased the accuracy to 78.50%. This demonstrates that EnerAgentic has acquired the core competencies required to serve as a research assistant for Integrated Energy Systems.
5.1 Limitations
Although EnerAgentic has made positive progress, this study still has certain limitations. First, while the current instruction dataset is substantial, its depth and breadth still have room for improvement. There may be deficiencies such as uneven knowledge coverage or insufficient data for specific niche scenarios. Second, EnerAgentic’s capability ceiling is constrained by its base model, unavoidably inheriting the base model’s inherent flaws in handling extremely complex reasoning such as multi-objective optimization under physical constraints, and it still carries the risk of producing hallucinations. Finally, the domain benchmark we constructed currently consists mainly of objective questions, and its evaluation dimensions are not yet comprehensive enough.
5.2 Future Work
Looking ahead, our work will unfold in the following aspects: First, we will continuously expand and optimize the instruction dataset, introducing more diverse data types and more complex research tasks. Second, we will construct a more comprehensive IES large model benchmark, incorporating subjective questions, multi-step reasoning tasks, and code execution validation to more thoroughly evaluate the model’s research assistance capabilities. Third, we will focus on exploring EnerAgentic’s capabilities with time-series data. IES research relies heavily on the analysis and prediction of time-series data such as load, electricity prices, and meteorological data. We will explore endowing the model with the ability to understand, process, and predict multivariate time-series data, making it a truly powerful assistant that spans the entire research workflow.
Reference
1. Touvron, H., et al.: LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971 (2023). doi: 10.48550/arXiv.2302.13971.
2. DeepSeek-AI, et al.: DeepSeek LLM: Scaling Open-Source Language Models with Longtermism. arXiv:2401.02954 (2024). doi: 10.48550/arXiv.2401.02954.
3. Yang, A., et al.: Baichuan 2: Open Large-scale Language Models. arXiv:2309.10305 (2023). doi: 10.48550/arXiv.2309.10305.
4. Yang, A., et al.: Qwen3 Technical Report. arXiv:2505.09388 (2025). doi: 10.48550/arXiv.2505.09388.
5. Yin, C., et al.: PowerPulse : Power energy chat model with LLaMA model fine‐tuned on Chinese and power sector domain knowledge. Expert Systems 41(3), e13513 (2024). doi: 10.1111/exsy.13513.
6. Zhang, L., Chen, Z.: Large language model-based interpretable machine learning control in building energy systems. Energy and Buildings 313, 114278 (2024). doi: 10.1016/j.enbuild.2024.114278.
7. Lee, S., et al.: LLM-based Question-Answer Framework for Sensor-driven HVAC System Interaction. arXiv:2507.04748 (2025). doi: 10.48550/arXiv.2507.04748.
8. Bi, Z., et al.: OceanGPT: A Large Language Model for Ocean Science Tasks. arXiv:2310.02031 (2023). doi: 10.48550/arXiv.2310.02031.
9. Wang, Y., et al.: AutoSurvey: Large Language Models Can Automatically Write Surveys. arXiv:2406.10252 (2024). doi: 10.48550/arXiv.2406.10252.
10. Zhu, M., Weng, Y., Yang, L., Zhang, Y.: DeepReview: Improving LLM-based Paper Review with Human-like Deep Thinking Process. arXiv:2503.08569 (2025). doi: 10.48550/arXiv.2503.08569.
11. Schmidgall, S., et al.: Agent Laboratory: Using LLM Agents as Research Assistants. arXiv:2501.04227 (2025). doi: 10.48550/arXiv.2501.04227.
12. Liu, Y.-X., et al.: RePower: An LLM-driven autonomous platform for power system data-guided research. Patterns 6(4), 101211 (2025). doi: 10.1016/j.patter.2025.101211.
13. Jin, H., Kim, K., Kwon, J.: GridMind: LLMs-Powered Agents for Power System Analysis and Operations. arXiv:2509.02494 (2025). doi: 10.48550/arXiv.2509.02494.
14. Small, H.: Co‐citation in the scientific literature: A new measure of the relationship between two documents. J. Am. Soc. Inf. Sci. 24(4), 265–269 (1973). doi: 10.1002/asi.4630240406.
15. Hu, E.J., et al.: LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685 (2021). doi: 10.48550/arXiv.2106.09685.
16. Jain, N., et al.: NEFTune: Noisy Embeddings Improve Instruction Finetuning. arXiv:2310.05914 (2023). doi: 10.48550/arXiv.2310.05914.
17. Reimers, N., Gurevych, I.: Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv:1908.10084 (2019). doi: 10.48550/arXiv.1908.10084.
18. Lewis, P., et al.: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. arXiv:2005.11401 (2020). doi: 10.48550/arXiv.2005.11401.
19. Sarthi, P., Abdullah, S., Tuli, A., Khanna, S., Goldie, A., Manning, C.D.: RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval. arXiv:2401.18059 (2024). doi: 10.48550/arXiv.2401.18059.
20. Li, H., et al.: CMMLU: Measuring massive multitask language understanding in Chinese. arXiv:2306.09212 (2023). doi: 10.48550/arXiv.2306.09212.
21. Huang, Y., et al.: C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models. arXiv:2305.08322 (2023). doi: 10.48550/arXiv.2305.08322.
22. Cobbe, K., et al.: Training Verifiers to Solve Math Word Problems. arXiv:2110.14168 (2021). doi: 10.48550/arXiv.2110.14168.
23. Hendrycks, D., et al.: Measuring Mathematical Problem Solving With the MATH Dataset. arXiv:2103.03874 (2021). doi: 10.48550/arXiv.2103.03874.
24. Suzgun, M., et al.: Challenging BIG-Bench Tasks and Whether Chain-of-Thought Can Solve Them. arXiv:2210.09261 (2022). doi: 10.48550/arXiv.2210.09261.
25. Clark, P., et al.: Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge. arXiv:1803.05457 (2018). doi: 10.48550/arXiv.1803.05457.
26. M.-A.-P. Team, et al.: SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines. arXiv:2502.14739 (2025). doi: 10.48550/arXiv.2502.14739.
27. Jain, N., et al.: LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code. arXiv:2403.07974 (2024). doi: 10.48550/arXiv.2403.07974.
28. Qin, Y., et al.: ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs. arXiv:2307.16789 (2023). doi: 10.48550/arXiv.2307.16789.
29. Zellers, R., Holtzman, A., Bisk, Y., Farhadi, A., Choi, Y.: HellaSwag: Can a Machine Really Finish Your Sentence?. arXiv:1905.07830 (2019). doi: 10.48550/arXiv.1905.07830.