综合能源系统研究需要领域深度和科学逻辑,而当前的大型语言模型(LLM)缺乏这些能力。为了弥补这一差距,我们开发了IES领域的研究助手 EnerAgentic 。通过采用 Generator-Validator Agent 流水线,我们自动构建了一个包含约56,000个样本的高质量监督微调数据集 。在此基础上,我们使用SFT对 Qwen3-14B-Base 模型进行了微调,并集成了检索增强生成(RAG)框架 。此外,我们提出了一种多智能体协同推理框架,该框架集成了 Planning、Retrieval、Reasoning 和 Tool-Execution Agent,以自主处理复杂的跨学科任务 。评估结果表明,EnerAgentic 在通用基准测试中全面优于开源模型 。至关重要的是,在特定领域评估中,EnerAgentic-RAG 达到了 78.50% 的准确率,显著优于其基座模型(45.00%),并展现出接近 GPT-5(82.50%)的极具竞争力的性能 。这验证了 EnerAgentic 的核心能力,即能够为IES领域的复杂数据分析、知识检索和仿真建模提供支持 。
1 引言
综合能源系统(IES)凭借其多能互补、高效低碳的技术特性,已成为现代能源系统的重要发展方向。在全球碳中和目标的推动下,综合能源系统依靠大数据分析、人工智能技术和先进传感网络,实现了能源生产、传输、存储和消费全流程的智能化管理与优化调度,显著提升了系统运行效率和可靠性。然而,综合能源系统涉及能源、电气工程、经济学、管理科学等多个领域知识的深度交叉融合,其知识库具有碎片化和快速演进的特点,给科研和教育工作带来了巨大挑战。
近年来,与大型语言模型(LLMs)相关的人工智能技术发展迅速,涌现出许多通用模型,包括LLaMA、Deepseek、百川和通义千问等。这些通用大型语言模型具备出色的语义理解和知识推理能力,能够高效整合多学科知识。但在科研实践中,这些通用模型在综合能源系统领域的表现并不理想,其 responses 往往缺乏足够的泛化能力,在该垂直领域的深度和精度方面存在明显不足。具体而言,研究表明,尽管通用大型语言模型在零样本学习方面表现出色,但在处理能源系统时,其在物理逻辑的可解释性方面受到限制。这一局限性主要源于其训练语料中缺乏综合能源领域的可靠知识,导致模型缺乏必要的领域背景和物理约束。因此,在面对复杂的综合能源系统科研任务时,例如制定分布式能源系统的多目标优化调度模型,通用模型往往会输出通用的数学公式,缺乏具体的变量定义和系统约束,无法内化严谨的研究逻辑。
能源领域特定大型模型的快速发展和完善在一定程度上弥补了通用模型的不足。它们在垂直领域的深度和精度足以解决专业的行业问题,甚至具备理解、整合和输出多模态数据的能力。例如,百度智能云与国家电网公司联合打造了“光明电力大模型”,这是国内首个百亿级多模态电力模型,涵盖了文本、图像、时序等丰富的行业数据,助力电力行业的数字化和智能化转型。

然而,这些领域特定模型的应用主要集中在工业生产和企业运维方面。由此训练出的模型普遍缺乏科研逻辑,存在答案不交互、反馈形式简单、推理过程简短等问题,无法满足研究人员和大学生的个性化需求,同样不适宜担任专业领域的研究助手。因此,存在一个关键缺口:现有的通用模型缺乏领域深度和物理约束,而行业特定模型则缺乏科学探究所需的必要逻辑。
为了填补这一缺口,解决综合能源系统领域在科研、行业决策等方面存在的难题,我们开发了EnerAgentic,一款面向综合能源系统(IES)垂直领域的研究助手。该模型利用自建的高质量领域数据集,通过整合监督微调(SFT)和检索增强生成(RAG)等步骤完成训练。它不仅能够充当知识渊博的行业专家提供精准答案,还能自动解析文献中的图表,快速梳理知识框架,并生成仿真代码以实现复杂的数据建模和潮流计算,旨在为综合能源系统领域的研究人员提供端到端的智能辅助。
2 相关工作
2.1 能源领域的大型语言模型
近年来,大型语言模型(LLMs)已从通用领域迅速发展到专门的垂直领域。Mirshekali等人和Amjad等人的研究表明,尽管大型语言模型在零样本学习和多模态数据处理方面展现出强大能力,但它们仍面临诸多挑战,包括计算成本高昂、领域特定数据集稀缺以及对物理逻辑的可解释性有限等。因此,需要进行领域特定的微调以及多智能体协同。为了克服这些局限性,研究人员通过领域特定知识微调,显著提升了模型在特定科学任务上的性能。例如,在电力系统领域,Yin等人利用中文和电力领域知识对LLaMA模型进行了微调,使其在文本生成、摘要和主题识别等任务中展现出极具竞争力的出色性能。在建筑能源领域,Zhang等人将SHAP(沙普利可加解释)技术与大型语言模型相结合,解决了暖通空调(HVAC,即采暖、通风与空调)系统中人工智能控制的“黑箱”问题,并生成了可解释的叙述性技术报告。Lee等人开发的JARVIS框架通过“专家大型语言模型”与“智能体”的协作,实现了关于暖通空调传感器数据的复杂问答与交互。在这些特定应用的基础上,Lin等人系统地探讨了生成式人工智能带来的范式转变,强调了其在智能能源系统研究和教育领域的变革潜力。
尽管大型语言模型在单一能源领域(如电力和建筑领域)取得了进展,但在更为复杂的跨学科综合能源系统(IES)领域的应用仍处于起步阶段。综合能源系统涉及电力、燃气、热力和氢能等多种能源载体的耦合与优化,这对模型的跨领域知识理解能力和复杂推理能力提出了更高要求。针对这一挑战,Jiang等人探索了视觉-语言模型中通用跨领域检索的适配机制,为整合异构领域知识提供了有价值的技术见解。为了有效管理这些相互关联的系统,研究人员认识到仅靠单一模型往往是不够的。最近,已有一些研究开始探索多智能体框架来解决复杂的能源问题。例如,Jin等人提出的GridMind系统是一个多智能体人工智能系统,它将大型语言模型与确定性工程求解器相结合,辅助电力系统分析。然而,目前尚无专门为综合能源系统研究任务设计的多智能体框架,该框架需整合多源知识检索、复杂数据分析、仿真工具调用以及学术内容生成等功能。本研究提出的EnerAgentic旨在填补这一空白。通过构建多智能体协同系统,它为综合能源系统领域的研究人员提供端到端的智能辅助。
2.2 用于自主科研的大语言智能体
在新兴的“AI for Science”范式推动下,大型语言模型(LLMs)辅助科学研究的能力已从简单的文本处理发展到更复杂、结构化的研究任务。在学术写作和文献分析领域,大型语言模型正显著加速知识合成过程。西湖大学的Wang等人开发的AutoSurvey系统,利用多模型评估实现了学术文献综述的自动化撰写。在这些早期自动化综述系统的基础上,Bao等人最近通过SurveyGen推进了这一领域,引入了一种质量感知框架,将文献质量评估融入检索增强生成(RAG)流程,以确保生成高度可靠且结构化的科学综述。同样,浙江大学的Zhu等人训练的DeepReviewer-14B模型,通过模仿人类专家评审过程,提高了自动化论文评审的可靠性。
除了文献处理,研究人员还开始探索自主研究代理。例如,Schmidgall等人提出的Agent Laboratory框架构建了一个大型语言模型代理,能够自主完成文献综述、实验执行和报告撰写。在能源领域,清华大学的Liu等人开发的RePower平台是一个由大型语言模型驱动的自主研究平台,能够独立执行电力系统领域中参数预测和优化等数据驱动的研究任务。这些研究凸显了大型语言模型作为“研究助手”的巨大潜力,为开发像EnerAgentic这样的特定领域自主代理奠定了理论和技术基础。
3 EnerAgentic
本节将详细阐述 EnerAgentic 的完整构建过程,该过程围绕四个核心技术模块展开 。
第一个是 领域指令数据生成 (3.1) ;作为模型的基础,该阶段涉及构建多源 IES 语料库,随后利用“Generator-Validator” Agent 流水线自动构建包含约56,000个高质量样本的SFT指令数据集 。
第二个模块是 模型微调 (3.2),我们选择了 Qwen3-14B-Base 作为基座模型 。利用 LLaMA Factory 框架,我们通过协同应用低秩自适应(LoRA)技术、微调噪声嵌入(NEFTune)、Dropout 正则化方法以及余弦退火学习率策略,进行了高效且稳定的训练 。
第三个模块是 多模态文档解析 (3.3),它为 EnerAgentic 配备了处理复杂文档的能力,通过集成光学字符识别(OCR)、表格结构识别(TSR)和文档布局识别(DLR)技术,将扫描的PDF等文件转换为结构化的 Markdown 格式 。
最后,RAG (3.4) 模块采用了基于树状组织检索的递归抽象处理(RAPTOR)方法,使模型能够从领域知识库中获取精确的上下文,从而提高回答的准确性并减轻“幻觉”现象 。
3.1 领域指令数据生成
3.1.1 构建综合能源系统语料库
为了使该模型具备研究助手的能力,本研究构建了一个多源、异构的综合能源系统(IES)领域语料库。其组成包括:
1)权威学术文献,如具有代表性的综述和高被引论文;
2)专业教材、行业标准和政府白皮书;
3)工程端资料,如开源代码库以及Matpower、Pandapower等仿真软件的技术文档,这些资料旨在提升模型在代码生成和工程实践方面的能力。
该语料库的构建遵循“检索-筛选-清洗”流程。
在数据检索阶段,我们基于 Web of Science、IEEE Xplore、ScienceDirect 和 CNKI 等数据库,使用“综合能源系统”等关键词进行检索。为确保语料库的时效性,文献的时间范围限定在2015年至2025年。
在数据筛选阶段,为保证文献的核心相关性和权威性,我们采用了文献计量学与专家人工判断相结合的多阶段筛选策略。
我们首先进行了关键词共现分析,以精确定位当前的研究热点。如下图所示,关键词共现网络关键词聚类图可视化了该领域复杂的关系和核心主题结构,其中高频关键词形成了不同的聚类,突出了高度互联的节点,如“综合能源系统”“能源管理优化”和“斯塔克尔伯格博弈存储”。这种网络结构方法不仅有助于划定语料库的语义边界,还揭示了不同子领域之间的紧密联系、知识演化的态势以及该领域内潜在的跨学科方向。这种聚类有助于划定语料库的语义边界。
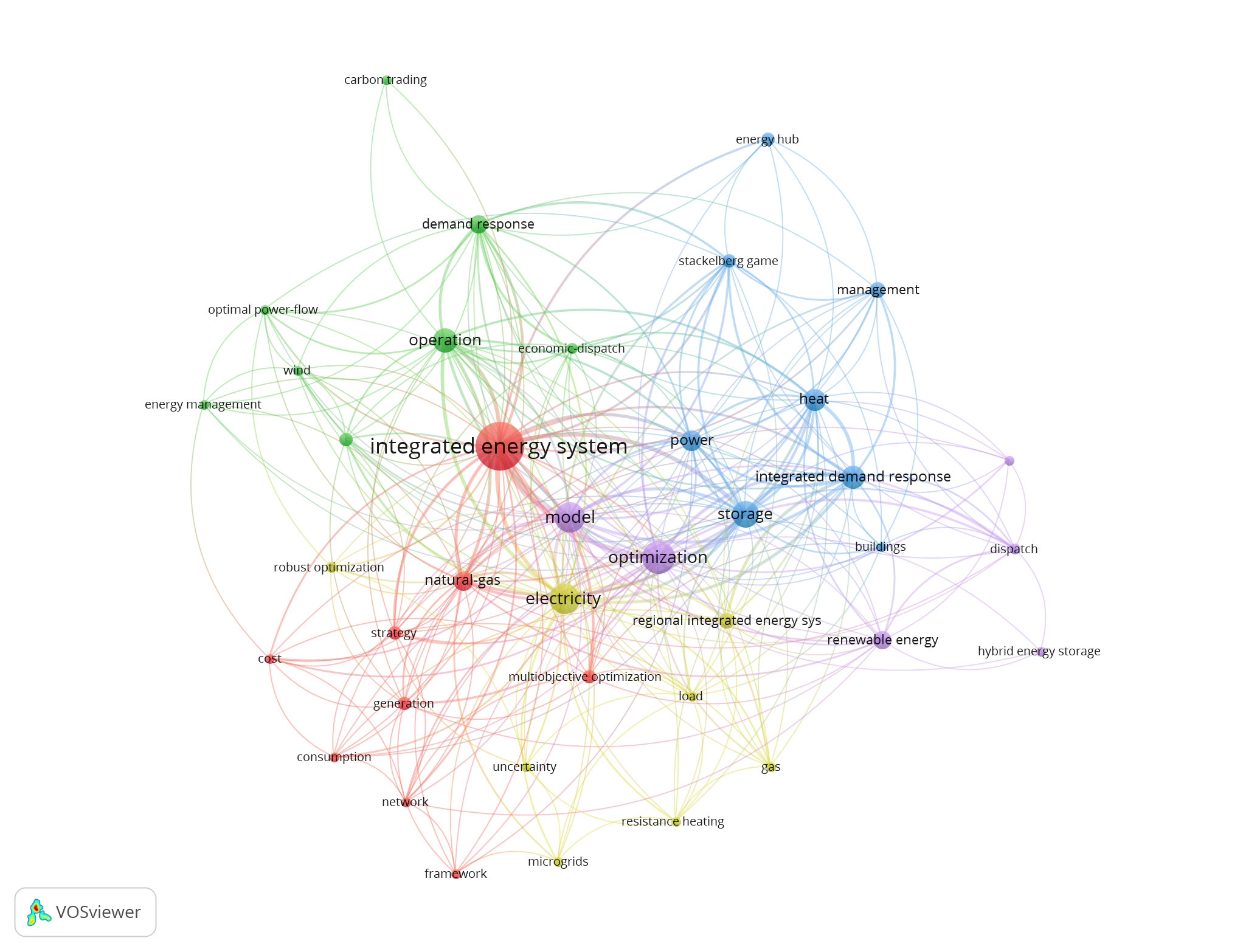
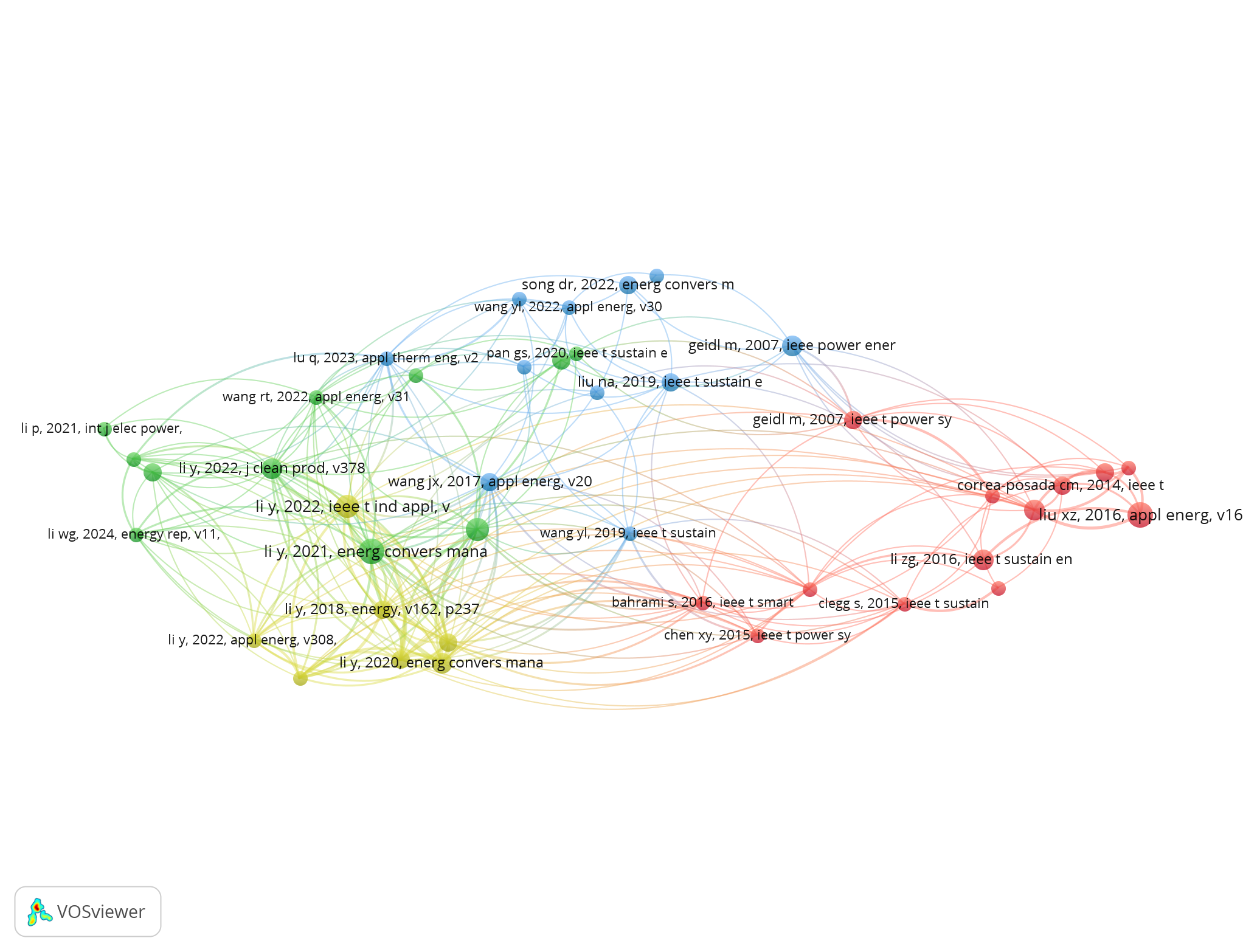
同时,我们应用了参考文献共被引分析来确定该领域的知识基础。下图所示的参考文献共被引网络揭示了关键文献之间的引用关系,突出了综合能源系统(IES)领域内最具权威性和基础性的文献。基于上述文献计量分析的最新结果,研究人员进一步手动审阅了文献的标题、摘要和关键词,剔除了相关性较低的文献。最终,选取了201篇高质量的中文文章和196篇高质量的英文文章作为核心学术语料库。
在数据清洗阶段,为了消除模型训练过程中无关内容的干扰,所有文献都经过了预处理和清洗。我们使用MinerU等工具将源PDF文件解析为结构化的Markdown格式,这一过程充分保留了文本和表格信息。同时,页眉、页脚、网址、作者简介和参考文献列表等非知识性内容被统一删除。处理后的语料库精准聚焦于综合能源系统的核心知识,为后续的模型训练提供了坚实的数据基础。具体而言,在学术论文PDF处理的常见场景中,MinerU首先利用其版式分析工具对PDF文档的页面结构、元素位置和排版特征进行分析,随后辅助光学字符识别(OCR)文本识别和数据提取过程,以确保识别结果的准确性和文档内容的结构化呈现。在这一工作流程中,版式分析与OCR的协同作用有效保证了PDF文本转换为结构化Markdown格式的准确性。根据公开信息,MinerU 2.5 1.2B在文档解析场景中的整体准确率达到90.67%,在中文文档图像场景的文本识别中达到96.7%的字符级准确率。然而,由于研究时间和人力限制,我们没有单独测试MinerU的OCR准确率,而是采用人工抽样检查作为解析文本的质量控制措施。当检测到解析错误时,会根据原始PDF文本进行纠正,以确保生成的Markdown文本的准确性。
3.1.2 生成种子数据集
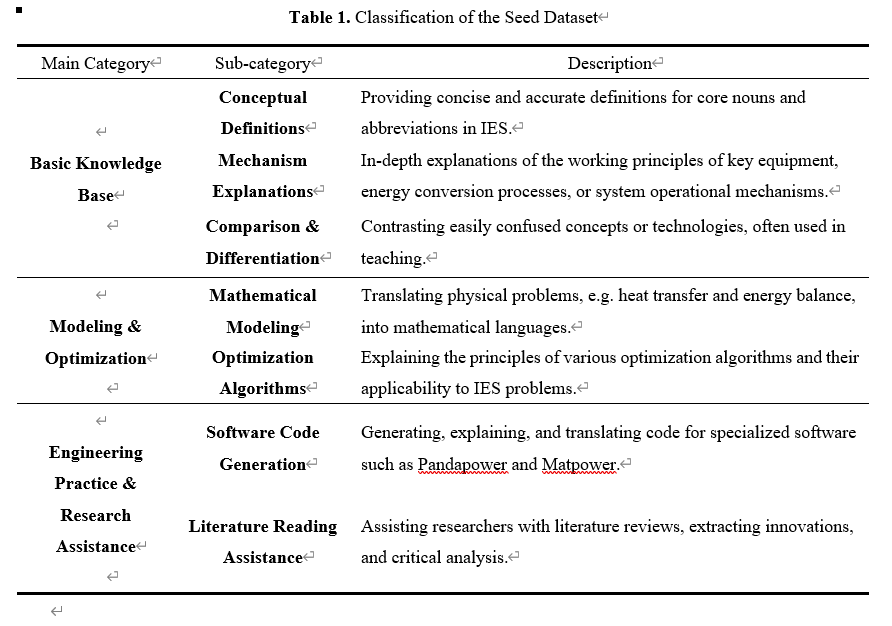
在种子数据集的生成过程中,我们根据该领域的研究需求,将IES数据手动分为以下3个主要类别和7个子类别。这些类别在表1中有详细说明。
基于上述内容,我们聘请了几位具有丰富IES背景的专家学者。每位专家负责特定类别的种子数据标注和生成。在此过程中,我们使用大语言模型补充和完善了现有的数据 ,最终经专家人工审核通过。这一过程耗时约3天,最终生成了涵盖3个主要类别和7个子类别的约2000多个种子数据样本。
3.1.3 生成器智能体 Generator Agent
基于种子数据集和垂直领域语料库的内容,我们设计了一个生成器智能体来生成候选问答对。
在构建高质量数据集的过程中,准确且高质量的提示词起着至关重要的作用。生成器智能体利用之前选定的种子数据集,调用GPT-4o模型的API来生成用于数据构建的提示词。这些提示词聚焦于综合能源系统,融入了问题格式、背景信息和任务目标等要素,以引导模型生成能源管理、存储优化和需求响应等典型场景的问答对。高质量的提示词提供了上下文和结构化信息,提高了生成结果的相关性和准确性,同时也为模型训练提供了参考模式,确保了一致性并降低了生成任务的复杂性。
基于生成的高质量提示词,生成器智能体将预处理文本文件中的问答对作为参考上下文嵌入到提示词中。它调用大型语言模型的API来生成候选问答对。在本研究中,生成器智能体使用 GPT-4o 来生成这些候选对。每次调用时,该智能体都会向大型语言模型API发送包含提示词模板、种子数据和生成参数(如温度、最大长度等)的请求,并接收生成的文本。这最终生成了大约 70,000 个候选问答对。这些候选对涵盖了综合能源系统领域的多个关键场景,如能源管理、存储优化和需求响应,为后续的数据筛选和模型训练提供了丰富的素材。
3.1.4 检验器智能体 Validator Agent
为确保微调数据集的质量和多样性,我们设计了一个包含质量过滤和重复控制功能的检验器智能体(Validator Agent),用于处理生成器智能体(Generator Agent)生成的候选问答对。该验证过程分为两个阶段:
阶段1:质量与格式过滤。此阶段利用大语言模型(LLMs)的评估能力。系统调用 GPT-4o API,自动评估候选问答对的语义连贯性、逻辑正确性、格式规范性以及答案相关性。被 GPT-4o 判定为“不合格”的样本,例如语义不连贯、问答不相关或存在格式错误的样本,便会被直接舍弃。
阶段2:重复控制与去重。为解决语义重复问题,本阶段采用基于TF-IDF的文本相似度检测方法。首先,将通过第一阶段的每个问答对的指令和输出字段拼接成单个文本文档,构建去重语料库。随后,使用 Scikit-learn 库中的 TfidfVectorizer 类,指定 jieba 为中文分词器,将整个语料库高效转换为 TF-IDF 向量矩阵。通过计算该矩阵中向量间的余弦相似度,可量化样本间的语义重叠度。本研究将相似度阈值设为0.7,当任意两个问答对的相似度得分超过该阈值时,系统判定它们高度相似,并仅保留一个具有代表性的样本。
经过这两个阶段的严格过滤,我们最终构建了一个约包含56,000个样本的高质量IES领域指令微调数据集。
3.2 微调 (Fine-Tuning)
EnerAgentic 选择 Qwen3-14B-Base 作为基础模型,并在配备了两块 NVIDIA A6000 GPU 的服务器上进行训练。为实现高效且稳定的微调,本研究采用了一种综合策略,将LoRA、正则化和动态学习率调度相结合。
关于微调框架,我们选择了 LLaMA Factory 框架,并采用了 LoRA 技术。LoRA的核心思想是冻结预训练模型的绝大多数权重,仅在特定层(如注意力层)引入小规模、低秩的可训练矩阵(可训练秩分解矩阵),以近似权重更新。在训练过程中,只更新这些新增的低秩矩阵的参数。这种方法既保留了预训练模型的丰富知识,又大幅降低了微调所需的计算资源和内存开销,实现了与全参数微调相当的性能。
为有效抑制在SFT阶段可能出现的过拟合现象,我们结合了两种正则化技术。首先,我们采用了经典的Dropout方法,在训练迭代过程中以一定概率随机“冻结”部分神经元。这迫使网络学习更稳健的特征表示,并防止神经元之间出现“协同适应”现象。其次,我们引入了NEFTune(微调中的噪声嵌入)技术,在训练时向嵌入层的输出向量中注入少量随机噪声。这种对输入表示的轻微扰动增加了训练难度,有效防止模型“记忆”有限的训练样本,从而增强其泛化能力。
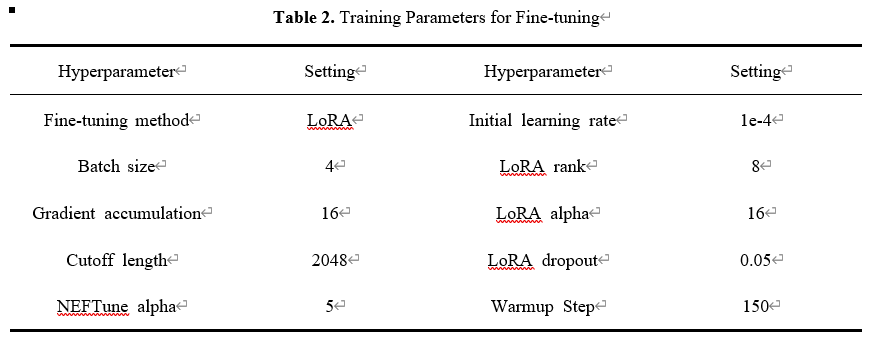
最后,为确保训练稳定性并加速收敛,我们采用了结合预热(Warm-up)和余弦退火(Cosine Annealing)的学习率调度策略。在训练初期,预热阶段从较低的初始学习率开始,逐渐增加到预设值,有效避免了在模型参数尚未稳定时可能出现的梯度爆炸或训练发散问题。预热阶段结束后,余弦退火策略接管学习率,使其随着训练步数的增加按照余弦函数曲线平滑衰减。这种先升后降的动态调整机制有助于模型在训练后期更精细地探索损失函数的局部最小值,提升最终的收敛效果。其余微调训练参数如表2所示。
3.3 RAG 框架与多智能体协同推理
为了解决大型语言模型(LLMs)固有的知识局限性和“幻觉”问题,EnerAgentic集成了检索增强生成(RAG)框架。该框架的核心机制是,在生成答案之前,模型会先从外部专业知识库中检索相关信息,并将其作为动态上下文。这显著提高了答案的准确性、时效性和可追溯性。本研究构建了一个针对综合能源系统(IES)领域的专业知识库,复用了 3.1.1 节中描述的IES语料库数据,并选取了具有高共引频次的论文和综述,以及技术手册中的事实性数据和信息。
然而,传统的RAG方法在处理能源领域中复杂的、多步骤推理的问答任务时存在局限性。在这类任务中,与问题相关的文本片段和答案之间往往存在语义差距,导致检索匹配精度下降,关键细节丢失。为了克服这一挑战,EnerAgentic 采用了 RAPTOR(递归抽象处理树状组织检索)检索方法。RAPTOR 是一种递归抽象处理技术,它以自下而上的方式构建分层知识索引。该方法从细粒度的原始文本片段开始,逐步提炼并生成粗粒度的摘要,最终形成结构化的内容树。这种树状索引结构使EnerAgentic在检索过程中能够平衡对长文档的全局语义理解和局部细节把握,有效解决了长上下文信息过载和上下文碎片化的问题,并显著提升了复杂查询的检索性能。
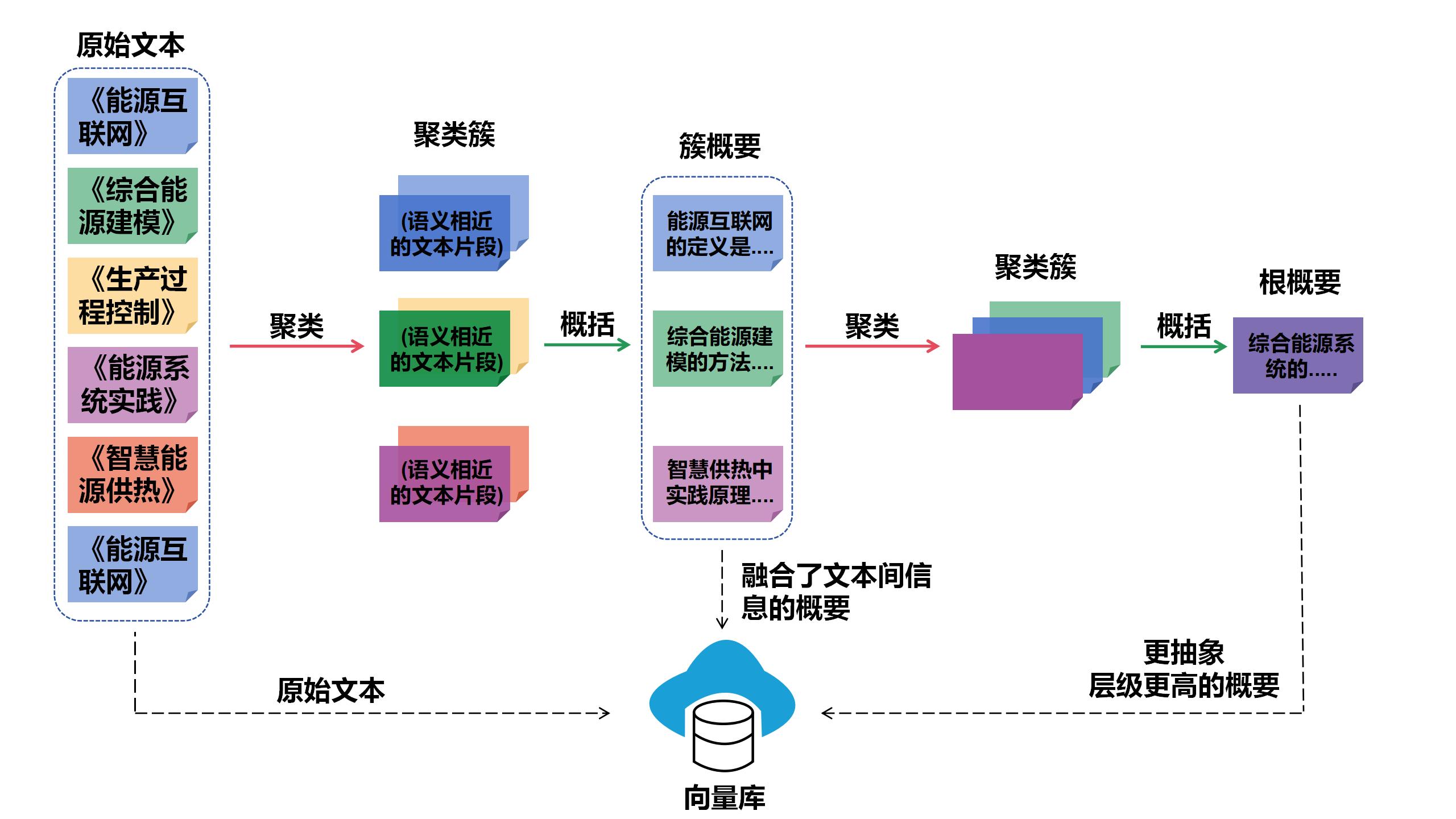
如上图所示,EnerAgentic采用RAPTOR策略构建了一个专为IES领域量身定制的多层级、树状结构知识索引。构建过程通过以下步骤解决了上下文碎片化问题:
1. 语义聚类:首先,对细粒度文本块进行分析,并根据语义相似度将其分组为文本簇,例如,将所有关于“能源供暖”或“过程控制”的技术细节归为一组。
2. 层次化总结:系统随后为每个组生成簇总结,例如,综合形成关于“IES建模方法”的连贯描述。这些总结被视为新的文本输入,再次进行递归聚类和总结,以形成更高层次的根总结,例如,高层次的“IES概述”。
3. 树状结构索引:这种自下而上的方法形成了存储在向量数据库中的树状结构索引,包含从叶节点(原始细节)到抽象的更高层次总结的所有内容。 当用户提交查询时,EnerAgentic利用这一结构在不同抽象级别检索信息。这使得模型能够弥合复杂推理任务中的语义差距——获取高层次概念以提供广泛的上下文,同时保留在叶节点中精准定位特定工程参数的能力。
此外,虽然RAPTOR方法能有效解决长文档的上下文碎片化问题,但在处理综合能源系统中对时间敏感的任务时,静态的本地知识库仍存在局限性,例如获取实时电价或最新气象趋势。为解决这一问题,我们集成了一种自适应双轨检索机制,该机制利用 Tavily 网络搜索 API 。具体而言,一个轻量级的基于大语言模型的路由器会评估传入查询的时间敏感性和理论深度。对于涉及基本物理机制、经典数学建模或成熟算法的查询,系统仅依赖本地RAPTOR数据库,以确保知识的权威性和严谨性。相反,对于需要实时数据或行业最新动态的查询,系统会触发网络搜索模块。在上下文融合阶段,从本地数据库检索到的高置信度树节点与从网络获取的最新事实片段会被拼接在一起。为降低网络来源的不准确信息干扰科学推理的风险,融合机制通过算法为本地经过同行评审的文献分配更高的置信权重。这种动态路由与融合方法使 EnerAgentic 在处理对时间敏感的研究任务时,能够保持学术严谨性。
3.4 多智能体架构
为了有效处理工程应用中智能能源系统领域内跨学科、多模态的复杂科研任务,EnerAgentic并未采用单一的线性生成模式,而是构建了一个多智能体协同推理框架。在3.1节中提到的生成器和验证器智能体完成离线指令数据构建后,系统在在线推理阶段引入了四个具有不同任务的智能体。通过状态转换和通信机制,它们协同完成从意图识别、知识检索到逻辑推理和代码生成的各项任务。
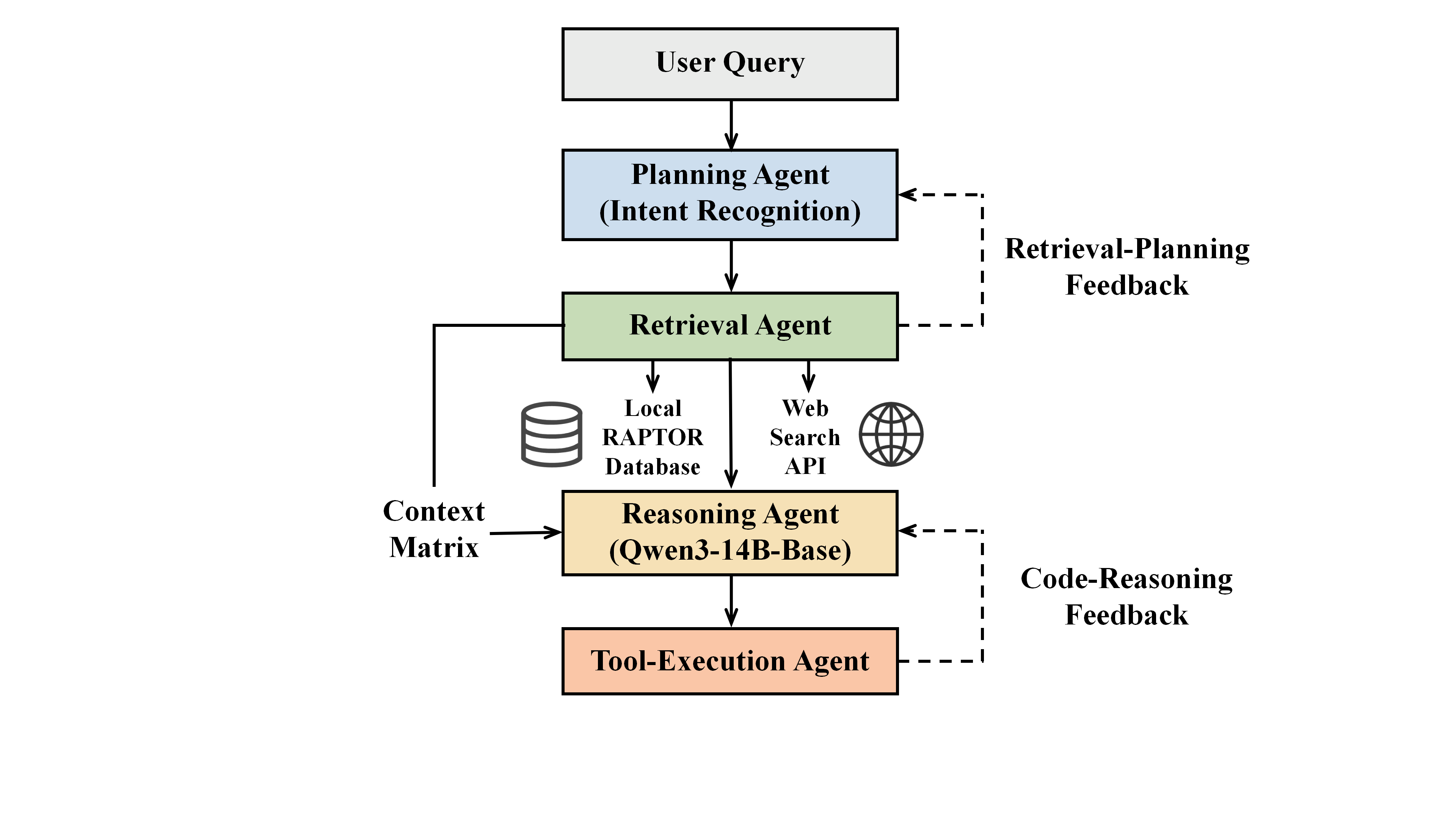
3.4.1 规划智能体
作为用户交互的主要入口,该智能体负责意图识别和复杂任务分解。规划智能体包含一个基于轻量级大语言模型(LLM)的路由器,用于评估输入查询的时间敏感性和理论深度。基于动态路由算法,该智能体自主决定后续任务流程:是将其分配至本地知识库进行深度理论检索,触发外部网络搜索以获取最新行业动态,还是直接进入多目标优化调度模型的构建过程。
3.4.2 检索智能体
该智能体负责执行特定的知识定位和事实核查。在接收到路由指令后,若任务涉及基础物理机制或经典数学建模,它会利用本地向量数据库中的RAPTOR递归检索技术,执行从宏观概述到微观技术细节的跨层级树状检索,从而解决长文档的上下文碎片化问题。若任务有时间要求,它将调用Tavily网络搜索API进行双轨检索。在上下文融合阶段,该智能体通过算法为本地经过同行评审的文献分配更高的置信权重,从而在融合碎片化网络信息的同时有效解决信息冲突,确保科学检索的严谨性。
3.4.3 推理智能体
推理智能体由经过监督微调(SFT)的Qwen3-14B-Base核心模型驱动。它负责接收经前序智能体清洗和结构化后的融合上下文,并执行逐步逻辑推理任务。在领域数据集上微调后,该智能体能够理解综合能源系统(IES)领域的物理约束和研究逻辑。面对分布式能源系统多目标优化等复杂科研任务时,它可以将宏观问题系统分解为变量定义、目标函数构建和系统约束确立等步骤,生成符合学术规范的高结构化专业文本。
3.4.4 工具执行智能体
综合能源系统领域的科研往往需要工程端的验证和计算。该智能体负责将推理智能体输出的数学模型或控制逻辑转换为可执行的Python或MATLAB仿真代码。此外,它还能基于编译器或仿真环境的反馈进行基本的代码语法验证和自我修正。
为实现轻量级实时交互式编码,该智能体在前端集成了基于 WebAssembly 技术的 Pyodide 运行时环境。这种设计使基本的综合能源系统数据分析和图表可视化能够直接在用户的浏览器安全沙箱内执行——例如,利用Pandas进行源荷数据清洗,调用Matplotlib绘制优化调度曲线——减少了云服务器的计算开销和通信延迟。对于计算密集型深度学习任务,如基于PyTorch框架构建的综合能源负荷预测模型,系统通过安全API将代码路由至后端隔离容器中执行,确保系统整体的安全性和稳定性。
同时,考虑到综合能源系统在底层控制逻辑和电气物理特性仿真方面的复杂性,仅依靠 Python 往往难以满足严苛的工程标准。为此,该智能体通过集成Python的MATLAB引擎API搭建了跨环境调用桥梁。这种机制不仅允许智能体根据任务需求自动生成和执行MATLAB脚本,还能动态配置和驱动后端Simulink模型,从而完成MATLAB程序验证。
3.4.5 智能体间通信机制
为确保多智能体系统在处理综合能源系统中的复杂科研任务时的效率和稳健性,EnerAgentic 中的上述四个智能体通过采用 JSON 格式提示模板的结构化消息协议来传递状态和进行通信。系统内四个智能体之间的关系呈现出一种层级顺序协作和局部反馈循环的结构。在设计提示词时,我们采用了两项原则来降低大模型的输出质量差异。第一项是协议化的输入和输出:规划智能体将分解后的任务抽象为搜索意图和关键词向量,并传递给检索智能体;检索智能体完成验证后,不会直接输出长文本,而是将高质量信息构建成上下文矩阵,作为内部提示字段注入到推理智能体的输入流中。第二项是强类型约束:在请求工具执行智能体输出时,提示词明确规定其必须输出有效的 Python 字典或包含特定依赖库的代码块,避免冗余的自然语言解释干扰后续的自动解析。
与传统的单向流水线模型不同,EnerAgentic 建立了两个内部反馈循环:代码-推理反馈循环和检索-规划反馈循环。代码-推理反馈循环是指,当工具执行智能体在 Pyodide 沙箱或 MATLAB 引擎中执行仿真代码时遇到错误,它会将捕获到的异常回溯和错误日志封装成 JSON 格式的反馈消息,并发送给推理智能体。推理智能体根据错误日志进行自我反思,修正其先前的数学模型或约束条件,然后重新发出代码生成指令。检索-规划反馈循环是指,当检索智能体无法在本地 RAPTOR 树索引中获取具有足够置信度的知识节点时,它会向规划智能体返回低置信度状态码。基于此,规划智能体会触发重试机制,重写搜索关键词,或切换路由策略至网络搜索模式。这种“生成-执行-反馈-修正”的闭环框架赋予了该模型应对综合能源系统科研任务的可靠能力。
4 模型能力评估
为了评估该模型执行与IES相关任务的能力,我们建立了一个全面的能力评估框架。该框架围绕六个关键维度构建:指令遵循、代码生成、学科计算、工具交互、逻辑推理和中文理解。基于此框架,我们设计了两个评估部分:一个通用基准测试和一个特定领域基准测试,以检验EnerAgentic的整体性能。
4.1 通用领域评估
在通用能力评估中,我们共选取了十个通用基准。为评估模型的中文理解能力,我们选用了 CMMLU 和 CEval 这两个大规模中文多任务基准。为评估学科计算和逻辑推理能力,我们使用 GSM8K 和 MATH-500 来测试数学解题能力。此外,还补充了 BBH 、ARC 和 Super-GPQA ,以考察模型在复杂推理、科学问答和高级专业知识方面的表现。为评估代码生成能力,我们采用了 Live-Code-Bench ,该基准侧重于评估实时代码生成和修复能力。为评估工具交互能力,我们选取了 Tool-Bench 来测试模型执行复杂工具调用的能力。最后,为评估指令遵循和常识推理能力,我们纳入了 HellaSwag 。
评估结果如上图所示。实验表明,在所有十个通用能力基准测试中,EnerAgentic的性能显著超过了对比模型Qwen3-14B-Base、DeepSeek-R1-Distill-Qwen-14B和Llama3-8B-Instruct。
与它的基础模型Qwen3-14B-Base相比,EnerAgentic在所有测试项目上都取得了显著的性能提升。这有力地证明,本研究采用的SFT策略不仅增强了模型的领域知识,还全面提升了其底层通用能力,特别是在学科计算(GSM8K、MATH-500)、逻辑推理(BBH、ARC)和代码生成(Live-Code-Bench)等维度。
此外,无论是在中文理解、常识推理还是复杂工具使用任务中,EnerAgentic的得分都处于领先地位。这表明,经过领域指令微调后,我们的模型的综合能力已经达到或超过了当前主流开源模型的水平。
4.2 能源领域专用测评
为了系统评估EnerAgentic在综合能源系统这一专业领域的性能,研究团队开发了一个特定领域的基准测试。该基准测试包含400个问题,聚焦于专业知识、推理能力、数据处理和实际应用等方面。然而,由于评估基准和训练数据集是独立开发的,因重叠导致的数据泄露难以避免。根据Meta公司的A. Abbas等人的研究,采用基于嵌入的语义去重方法可以有效减轻此类污染。为确保评估的客观性,防止测试集与训练数据之间存在重叠,我们利用了DeepSeek-R1 API,并实施了上述研究中提出的SemDeDup策略。与传统的基于关键词匹配或N-gram的方法不同,SemDeDup旨在识别和消除那些在语法上虽不相同但语义重叠度高的冗余数据。其流程首先是采用嵌入模型将每个文本或图像投影到高维特征向量中。为优化计算效率,会使用诸如K-means之类的聚类算法将大规模数据集划分成不同的簇。在每个簇内,计算样本向量之间的余弦相似度,并以预先设定的0.7作为判定阈值。如果评估基准中的某个样本与训练数据集中的任何实例之间的相似度超过该阈值,则认为它们在语义上是重复的;随后,评估基准中存在重叠的样本会被系统地剔除,从而确保测试集和训练集之间不存在语义重叠,维护评估过程的完整性和公平性。
在这个经过严格筛选的基准测试基础上,我们进一步使用面向摘要评估的召回导向型替补(ROUGE)和双语评估替补(BLEU)指标,对生成的回答的语言精确性和语义保真度进行了评估。ROUGE主要衡量生成文本与参考答案之间的n-gram重叠以及最长公共子序列,重点关注召回率和整体语义对齐情况。相反,BLEU评估n-gram匹配的精确性,因此对确切的措辞、特定术语和结构严谨性高度敏感。
如上图所示,我们将EnerAgentic与其基础模型Qwen3-14B-Base以及几款最先进的商业大型语言模型(包括GPT-4o、Qwen3-Plus和DeepSeek-Chat)进行了比较。评估结果显示,EnerAgentic具有显著的性能优势。在ROUGE指标方面,虽然各模型的召回率(R)得分相对接近,但EnerAgentic取得了明显更高的精确率(P)得分,从而在Rouge-1、Rouge-2和Rouge-L中获得了最高的综合得分。这表明EnerAgentic能更准确地捕捉局部关键词和整体结构流畅性,且不会生成冗余或无关信息。
最值得注意的是,EnerAgentic在BLEU得分上表现出显著的优势。例如,其BLEU-1得分接近0.47,几乎是该任务中表现最佳的商业模型的两倍。由于BLEU会对确切词汇匹配的偏差进行严厉惩罚,这种显著的领先优势表明,有监督微调过程成功地将深厚的IES领域知识植入了模型中。像GPT-4o这样的通用模型虽然具备强大的基础推理能力,但无法输出IES垂直领域所需的严谨学科术语、复杂公式和特定格式。EnerAgentic填补了这一空白,证明了其作为专业领域助手的有效性。
为了严格验证EnerAgentic在现实世界中的实用性和准确性,我们采用了全面的人工评估方法。我们招募了五名人类评估员,他们均是在IES领域拥有扎实学术背景的学生,负责手动评估模型输出。
评估员的任务是审查针对我们特定领域基准中400道客观题生成的 responses。评估涵盖了五个模型的输出:Qwen3-14B-Base、EnerAgentic、EnerAgentic-RAG、GPT-4o和GPT-5。为确保公平性并消除主观偏见,评估以严格的盲审方式进行;标注员完全不知道每个response是由哪个模型生成的。他们接到的指示是,根据自己的专业领域知识来判断每个输出的绝对正确性,而非基于主观偏好。
评估结果如表所示。基础模型在专业数据集上的准确率为45.00%,这表明通用大型模型严重缺乏IES领域的专业知识,无法准确回答专业问题。同样,即便是像GPT-4o这样先进的商业模型,准确率也仅为61.75%,这进一步凸显了通用模型在面对高度专业化的工程推理任务时存在的局限性。经过微调的EnerAgentic模型准确率达到70.75%,显著优于GPT-4o。这证实了监督微调(SFT)有效地为模型注入了领域知识和研究逻辑。在监督微调模型的基础上整合RAG框架后,EnerAgentic-RAG模型的准确率达到78.50%。值得注意的是,这一性能缩小了与最先进的商业模型GPT-5(得分82.50%)之间的差距。这表明,作为外部知识库的RAG有效弥补了模型参数化知识的不足,进一步提高了答案的准确性和可靠性,使EnerAgentic成为IES领域极具竞争力的专业研究助手。
为直观展示针对IES领域定制的SFT所带来的具体改进,以及凸显EnerAgentic在处理复杂工程推理任务方面的优势,我们开展了一项聚焦城市分布式能源系统多目标优化调度的案例研究。如图97所示,我们向该模型呈现了一个包含光伏发电、风能和储能设备的特定场景。指令要求该模型构建一个数学模型,以优化实时调度,实现三个相互冲突的目标:最大化可再生能源利用率、最小化电池充放电循环(以延长使用寿命)以及最小化系统整体运行成本。

对比结果显示,这两个模型在推理深度上存在明显差异。基础模型Qwen3-14B不仅提供了相对通用、缺乏特定上下文的公式,还存在明显的物理和数学逻辑缺陷。例如,为了最大化可再生能源利用率,其提出的目标函数简单地将可再生能源发电量与电池充放电量相加。这种表述在数学上是不合理的,完全忽略了基本的能量平衡原理,因为它无视了能量流动的方向性以及这些组件在电力系统中所扮演的不同物理角色。与之不同的是,EnerAgentic没有急于下结论,而是生成了一个结构清晰、内容全面的解决方案。它系统地将问题分解为变量定义(例如,定义时间步长t和功率输出)、制定精确的多目标函数,并建立了必要的系统约束。这种结构化的输出严格遵循学术建模标准,表明EnerAgentic已经成功内化了科学建模所需的研究逻辑,其能力大大超过了通用大型语言模型。
因此,在性能方面,EnerAgentic比开源大型模型表现出更好的数学推理能力和指令遵循能力。它在特定领域数据集上的表现也十分出色,具备处理综合能源系统(IES)任务的强大能力。
然而,执行现实世界中的综合能源系统任务往往需要超越静态的数学公式推导,动态调用外部工程工具。因此,为了进一步证明所提出的多智能体协同推理框架的实际有效性,我们展示了第二个案例研究,重点是动态控制系统仿真和MATLAB代码生成。如图10所示,该模型的任务是为600MW发电机组的选择性催化还原(SCR)脱硝系统设计氨喷射控制策略。输入提示包含特定的物理参数和严格限定的环境约束。

当用户输入包含复杂物理参数和严格约束的提示时,规划智能体首先作为意图识别的入口。它将此识别为工程控制和代码生成的混合任务。因此,它将该任务分解为两个步骤:第一步是理论层面控制逻辑的推导,第二步是工程层面MATLAB仿真代码的生成和可视化。规划智能体激活检索智能体,在本地向量数据库中搜索与“大时滞”系统和“SCR脱硝前馈-反馈串级控制”相关的理论知识。这些高可信度的专业知识被打包成上下文矩阵,并传输给推理智能体。推理智能体收到上下文后指出,用户的条件要求很高,单一的反馈控制无法满足需求;它推导出前馈-反馈串级控制或史密斯预估器的逻辑,并输出一阶加纯滞后(FOPDT)传递函数的数学模型。最后,工具执行智能体将推理智能体输出的传递函数和控制逻辑转换为相应的MATLAB代码。通过集成的MATLAB引擎API桥接机制,它在后台实际执行该代码,计算超调量和调节时间,并将生成的两条响应曲线返回给用户。在此过程中,如果MATLAB引擎出现错误,工具执行智能体将错误日志封装并发送回推理智能体,以修改代码指令后重新执行,从而确保代码的正确性。
此工作流验证了EnerAgentic不仅仅是一个对话模型,更是一个可付诸行动的研究助手,能够与专业工程软件交互,自动解决复杂的、受约束的动态系统问题。
4.3 模型推理能力压测
为确保EnerAgentic在实际研究场景中的实际部署可行性,我们进行了全面的推理性能压力测试。本次评估模拟了高并发使用环境,以评估模型的吞吐量、响应延迟和系统稳定性。
4.3.1 实验设置与指标
压力测试采用标准化的基准测试框架进行。我们模拟了200个并发用户同时发送请求的高负载场景,请求总数为1000个。为全面评估推理效率,我们采用了以下关键指标:
- 首 token 生成时间(TTFT):衡量从提交请求到生成第一个 token 所用的时间。这是用户感知响应性(即时性)的最关键指标。
- 每输出 token 时间(TPOT):表示预填充阶段后生成单个 token 所需的平均时间,反映模型的解码速度。
- 吞吐量(tokens/s):所有并发请求每秒生成的总 token 数,表明系统的最大服务能力。
- 延迟:完成一个请求的端到端总时长。
4.3.2 性能分析
压力测试的定量结果如下图所示。在200个并发线程的负载下,EnerAgentic表现出卓越的稳定性,实现了100%的请求成功率,零失败。
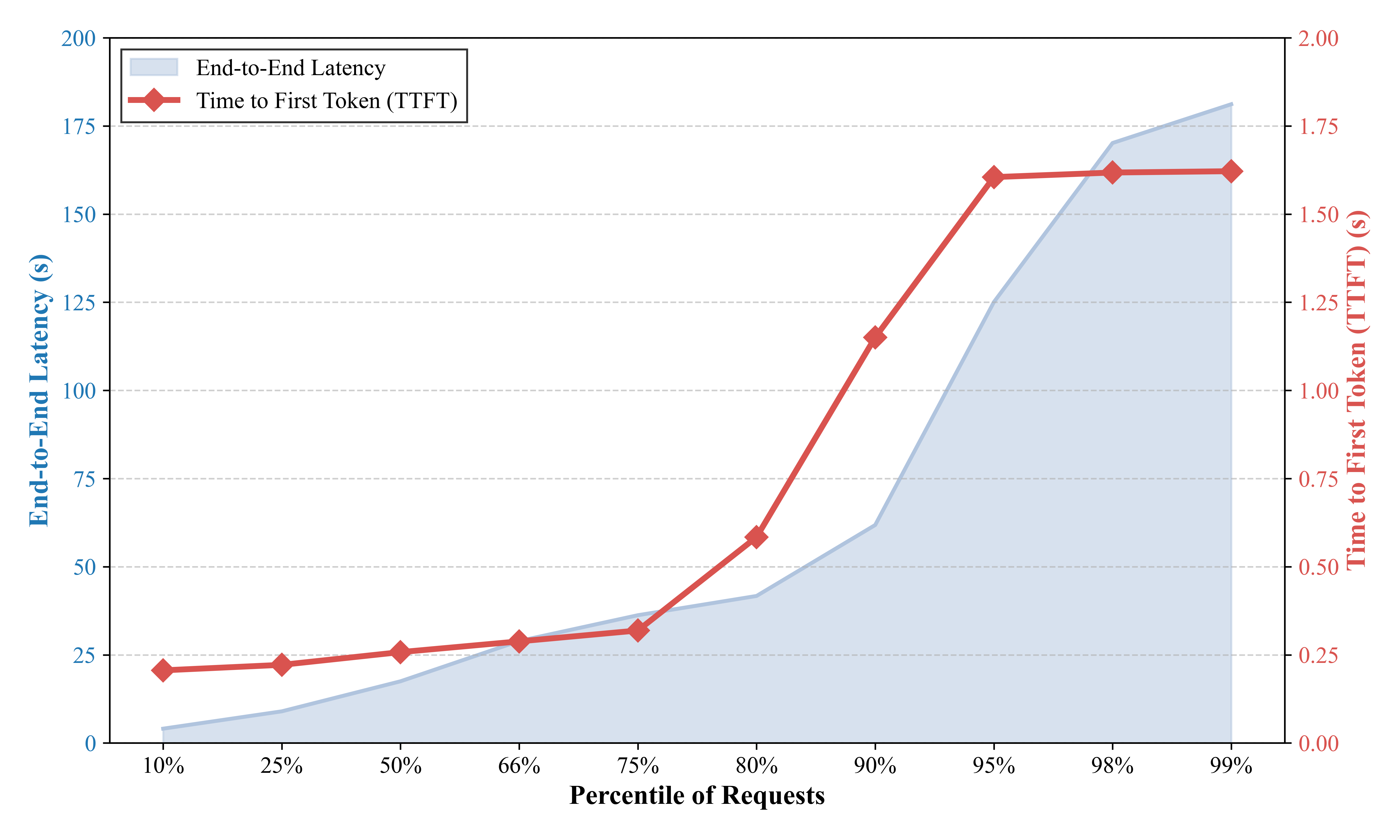
在响应速度方面,该模型的平均首次令牌输出时间(TTFT)仅为0.4268秒。即使在第99百分位,TTFT也保持在1.62秒左右,这确保了即使用户量达到峰值,用户也能获得近乎即时的反馈。在生成效率方面,该系统的总输出吞吐量达到了1270令牌/秒(tok/s),平均每令牌生成时间(TPOT)约为0.1073秒。
虽然记录的平均端到端延迟为29.71秒,但这是由于高并发设置(200名用户)以及任务的长上下文特性(每个请求的平均输出约为301个令牌)所致。测试证实,EnerAgentic具备强大的服务能力,能有效平衡高吞吐量和低交互延迟,适用于多用户科研平台。
5 讨论与未来方向
5.1 局限性
尽管EnerAgentic已取得积极进展,但本研究仍存在一定局限性。首先,从数据和评估的角度来看,虽然当前的指令数据集规模较大,但其深度和广度仍有提升空间。可能存在知识覆盖不均衡、特定小众场景数据不足等缺陷。同样,我们构建的领域基准目前主要由客观题组成,其评估维度尚不够全面。其次,在模型能力和架构方面,EnerAgentic的能力上限受到其基础模型的限制。它不可避免地继承了基础模型在处理极复杂推理(如物理约束下的多目标优化)时的固有缺陷,且仍存在生成幻觉内容的风险。此外,尽管EnerAgentic在文本生成、代码合成和逻辑推理方面表现出色,但其基础架构目前依赖于纯文本基础模型。目前,该系统借助外部OCR工具来解析学术文献中的图表、复杂的IES架构图和模拟曲线。然而,这种僵化的图像到文本的转换流程不可避免地导致视觉拓扑信息的严重丢失以及多模态上下文的剥离。因此,在处理需要图文联合理解的复杂科学任务时,该模型的能力受到显著制约。
5.2 未来方向
展望未来,我们的工作将沿着几个关键维度展开,以解决上述局限性。首先,我们将持续扩展和优化指令数据集,引入更多样化的数据类型和更复杂的研究任务。同时,我们将构建一个更全面的IES大模型基准,纳入主观问题、多步推理任务和代码执行验证,以更全面地评估模型的研究辅助能力。其次,为解决多模态局限性,未来的研究将超越传统的OCR+LLM范式。短期内,我们计划开发一个专门的IES视觉代理作为前端感知模块。该代理的任务是将复杂的能源网络图转换为高维图数据或结构代码表示,然后可以无缝集成到我们现有的多代理框架中。从长远来看,我们的目标是将基础系统迁移到原生的多模态大型语言模型(MLLMs)。通过引入视觉编码器,我们可以实现文本指令与IES视觉数据之间的基础特征对齐。这种演进最终将使系统具备端到端的多模态推理能力,使其能够直接理解科学文献中的复杂插图和模拟曲线。最后,我们将专注于探索EnerAgentic处理时间序列数据的能力。由于IES研究在很大程度上依赖于对时间序列数据的分析和预测——例如负荷曲线、电价和气象条件——我们将探索赋予模型理解、处理和预测多变量时间序列数据的能力,使其成为一个真正强大的、涵盖整个研究工作流程的助手。
6 结论
本研究成功开发了EnerAgentic,这是一款多智能体大型语言模型,专门用作IES领域的综合研究助手。在数据处理方面,我们设计了生成器-验证器智能体流水线,从多源领域语料库中自主合成了一个包含约56,000个样本的高质量SFT数据集。在架构上,我们提出了一个由规划、检索、推理和工具执行智能体组成的多智能体协作推理框架。该框架通过基于RAPTOR的递归检索机制和双轨网络搜索来解决上下文碎片化问题,并嵌入了Pyodide和MATLAB引擎用于可执行代码验证。该系统具有内部的代码推理和检索规划反馈循环,将大型语言模型从静态生成器转变为动态的、自我修正的科学工作流引擎。大量评估表明,EnerAgentic在IES领域展现出极具竞争力的科学研究能力。虽然与前沿模型GPT-5相比仍存在性能差距,但我们的系统显著优于GPT-4o等先进的商业模型,成功弥合了通用语言智能与严谨工程逻辑之间的鸿沟。尽管如此,考虑到IES的复杂性,我们认识到当前系统仍存在一定的局限性,需要持续改进以充分发挥其在更广泛科学工作流中的潜力。
-
Previous
EnerAgentic:Multi-Agent Large Language Models for Assisting Scientific Research Tasks in Integrated Energy Systems -
Next
大模型微调后暴露API方案比较